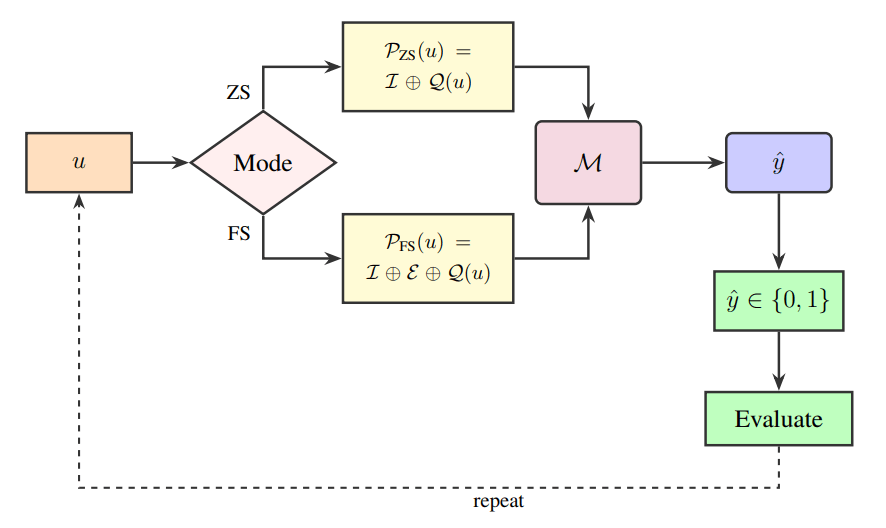
DPBench: Structural Determinants of Multi-Agent LLM Coordination Under Simultaneous Resource Contention
Najmul Hasan, Prashanth BusiReddyGari
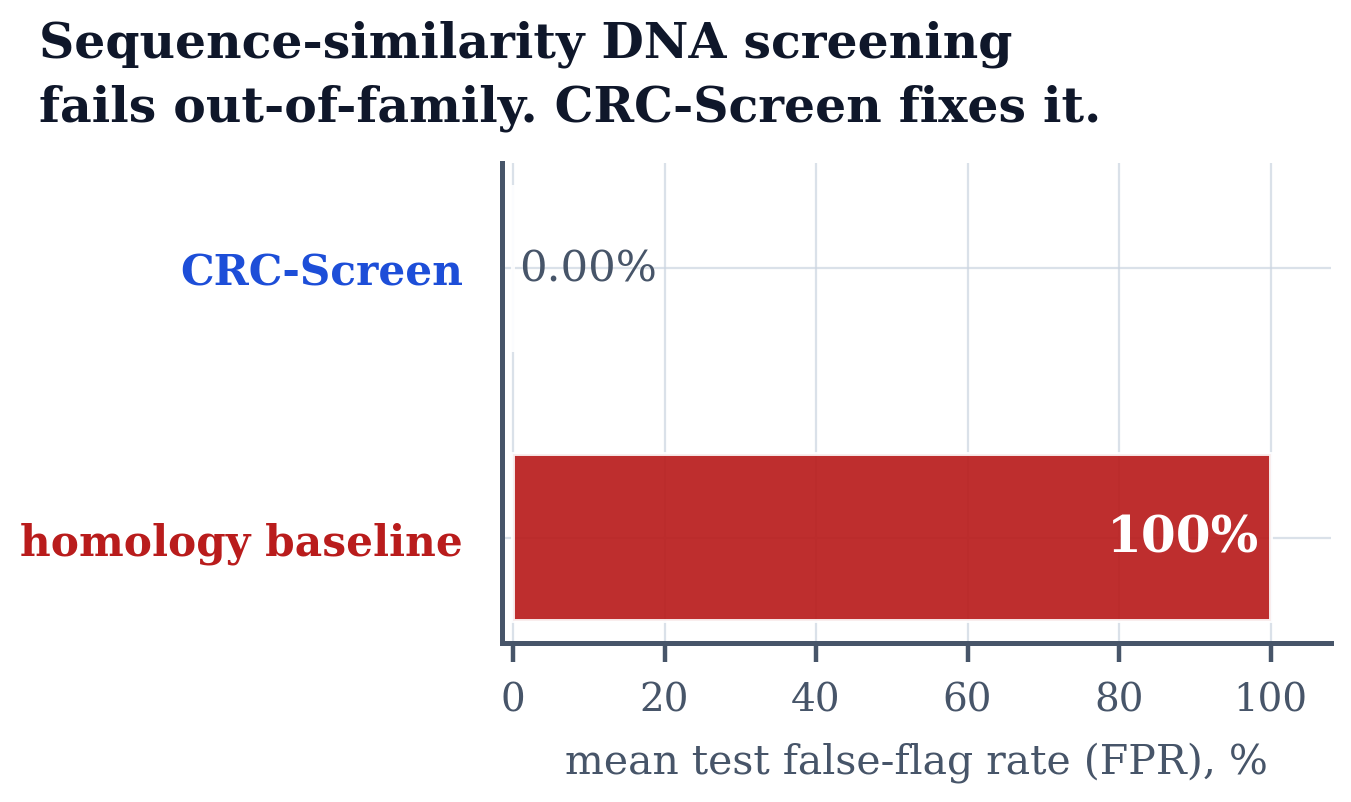
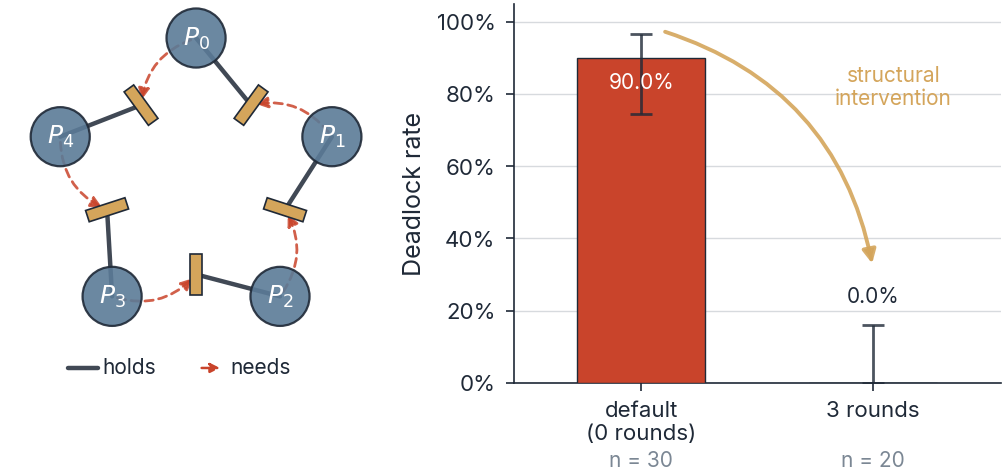
We present DPBench, a benchmark for evaluating coordination in multi-agent systems built from large language models. Existing benchmarks measure task-level success under a fixed protocol; the structural conditions under which coordination succeeds or fails at all have not been characterised. DPBench adapts the Dining Philosophers problem into a controlled testbed where the action protocol, the communication structure, the prompting strategy, and the group size each vary independently. We evaluate five frontier LLMs (GPT-5.2, Claude Opus 4.5, Grok 4.1, Gemini 2.5 Flash, Llama 4 Maverick) against a uniform-random baseline. Under simultaneous action at N=5 with the default prompt, deadlock ranges from 25.0% (95% Wilson CI [11.2, 46.9]) for GPT-5.2 to 90.0% [74.4, 96.5] for Gemini 2.5 Flash; sequential action is solved by three of the five LLMs plus the random baseline. Holding the model fixed at Gemini 2.5 Flash, three protocol variables drive deadlock from 90% to a 0% point estimate (Wilson upper bound 16.1% at n=20): three rounds of pre-commitment communication (vs. single-round 86.7%), a prompt encoding a classical concurrency primitive (0.0% for resource-ordering and symmetry-breaking, against 100% for the minimal prompt), or doubling the group from N=5 to N=10 (90.0% to 10.0%). Single-round messaging and memory of past timesteps do not change the rate at the sample size we ran. On the model that fails most, whether it coordinates or deadlocks is determined by the protocol, not by raw capability.